Procesamiento y calidad de datos
|
En este módulo aprenderás a determinar si los datos se ajustan a tu finalidad y cómo la revisión de las incidencias y alertas de datos de GBIF puede ayudarte a procesar los datos que usas para tu investigación. |
En función de tu pregunta de investigación, tendrás que decidir si los datos/conjunto de datos disponibles se ajustan con tu objetivo. Esto incluirá la valuación de la calidad de los datos.
|
En este vídeo (12:26), analizarás unos de los principios de aptitud para el uso y control de calidad. La audiencia de este vídeo está dirigida a los publicadores de datos, sin embargo muchos de los mismos principios se aplican e los usuarios de datos. Si no puedes mirar el vídeo Youtube incorporado, lo puedes descargar localmente en la página Files for download. |
Determinación de aptitud para el uso
Para una persona, los datos identificados al nivel de Genes pueden ser suficientes para ejecutar modelos de nichos ecológicos. Para una persona que estudia un taxón específico, esos mismos datos en el ámbito de genes serán mucho menos útiles que los casos más detallados con registros con información de subespecies.
Según los principios que Arthur Chapman analiza en el Principles of Data Quality, se debería reflexionar sobre cuestiones importantes sobre los datos para ayudarle a decidir si los datos son suficientemente fiables o útiles para su objetivo:
-
¿Cuánto aptos son los datos? Por ejemplo, ¿las identificaciones son actuales y fueron realizadas por expertos reconocidos?
-
¿Hasta qué punto son puntuales los datos? ¿Cuándo se pusieron a disposición los datos? ¿Con qué frecuencia han sido actualizados?
-
¿Hasta qué punto los datos son completos o exhaustivos? ¿En qué medida cubren los datos un momento, lugar o ámbito concretos?
-
¿Hasta qué punto los datos son coherentes? ¿Son los datos en cada campo de la misma tipología? ¿Se recogieron los datos utilizando los mismos protocolos documentados?
-
¿En qué medida los datos son relevantes? ¿En qué medida el conjunto de datos es similar a otros que han sido utilizados con éxito para el mismo objetivo?
-
¿En qué medida son detallados los datos? ¿Cuánta resolución tienen los datos? ¿A qué escala pueden utilizarse los datos para elaborar mapas?
-
¿Son los datos fáciles de traducir? ¿Está el conjunto de datos (meta datos) documentado de manera clara y concisa?
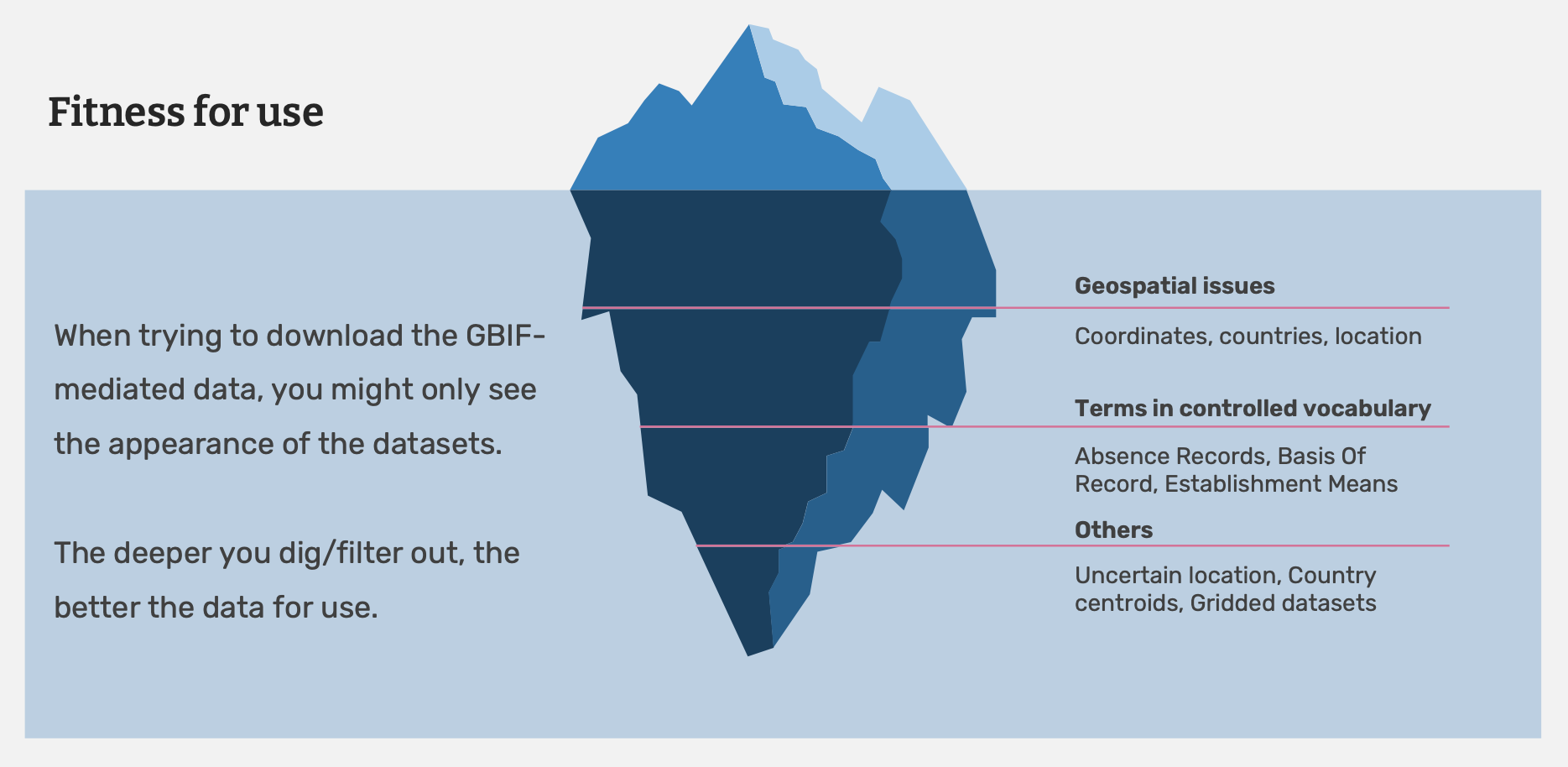
Evaluación de calidad de datos
Si usted decidió que un conjunto de datos es apto para su objetivo, necesita examinar más a fondo el conjunto de datos y completar el procesamiento tras la descarga de los datos mismos. Las descargas de GBIF contienen datos procedentes de diversas fuentes y puede que los datos probablemente varíen en sus medidas de calidad. Conocer las propriedades de los datos que posee le ayudará a entender las formas en las que puede y no puede limpiar, validar y procesar los datos.
| A continuación encontrará una selección de lectura de la guía de Arthur Chapman "Principios de la calidad de datos". Full document, Se pueden encontrar referencias y traducciones en GBIF.org. |